Research
Our research topics include, but are not limited to, the following areas:
CPU Microarchitectures and Multi-core Architectures
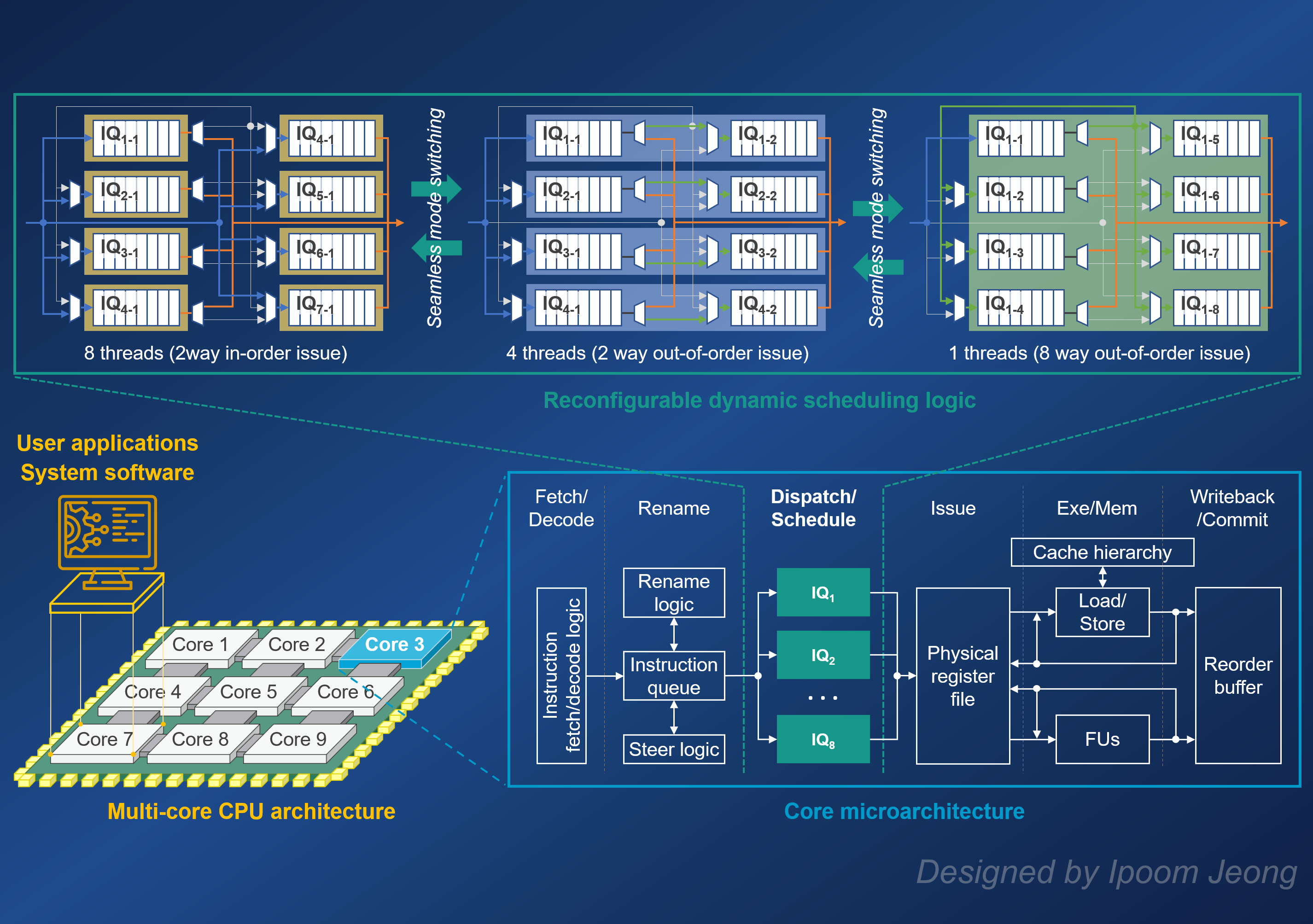
The Central Processing Unit (CPU) serves as the foundation of modern computing systems by executing applications and system software, managing hardware resources, and coordinating interactions with memory and I/O devices. Our research explores advanced CPU microarchitectural techniques—including speculative execution, dynamic scheduling, and early resource reclamation—as well as emerging multi-core architectures such as heterogeneous multi-core systems and Simultaneous Multithreading (SMT), with the goal of improving performance, scalability, and energy efficiency.
Representative Publications

GPGPU and Accelerator Architectures
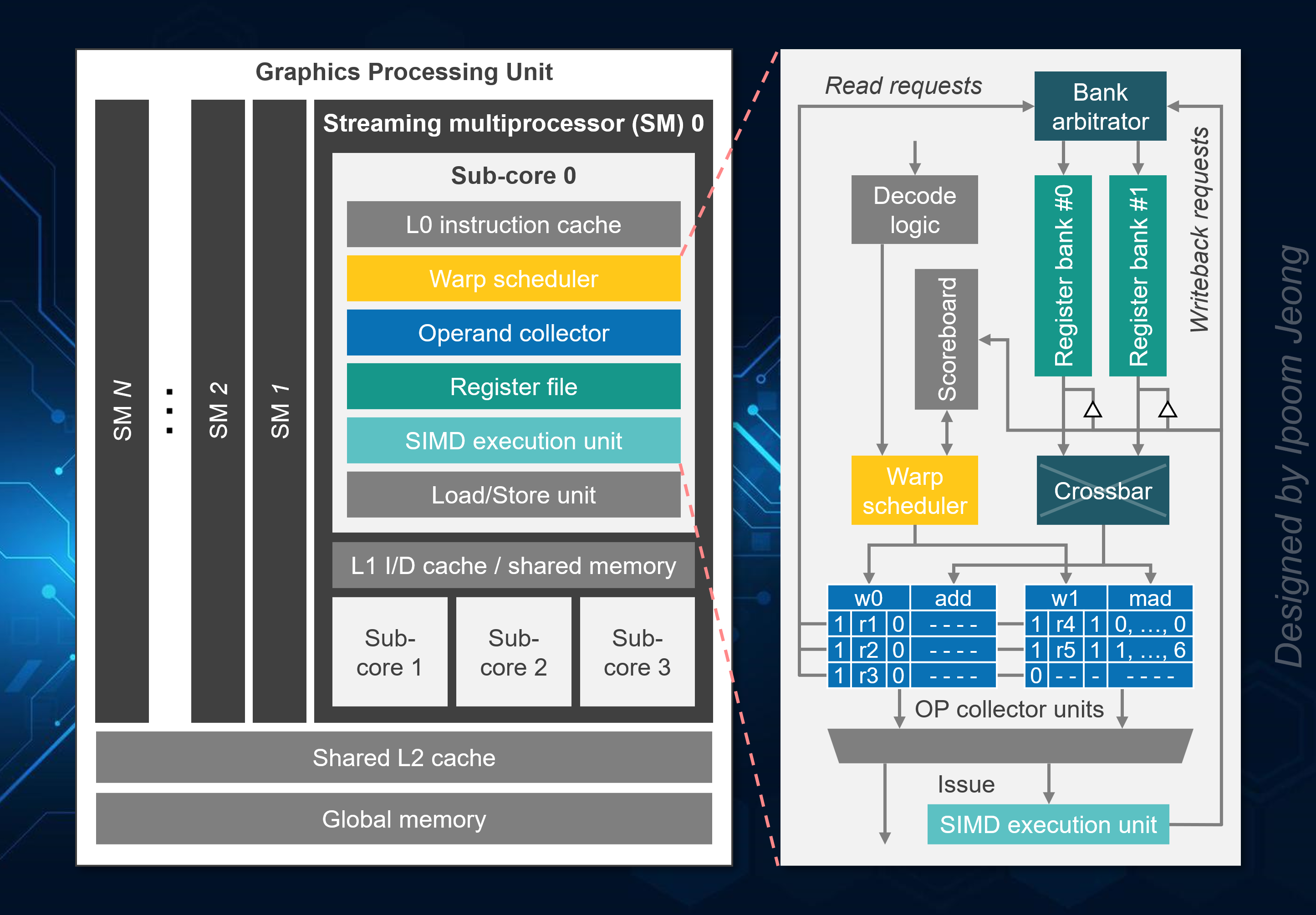
Emerging applications with diverse computation patterns have driven the development of specialized hardware designed to deliver optimal performance per watt for these tasks. We are exploring energy-efficient architectures for General-Purpose Graphics Processing Units (GPGPUs) and Neural Processing Units (NPUs). In addition, we are investigating various use cases for on-chip accelerators, which can offload specific tasks from the CPU to specialized hardware units to alleviate datacenter/system taxes.
Representative Publications

Emerging Interconnect Technologies
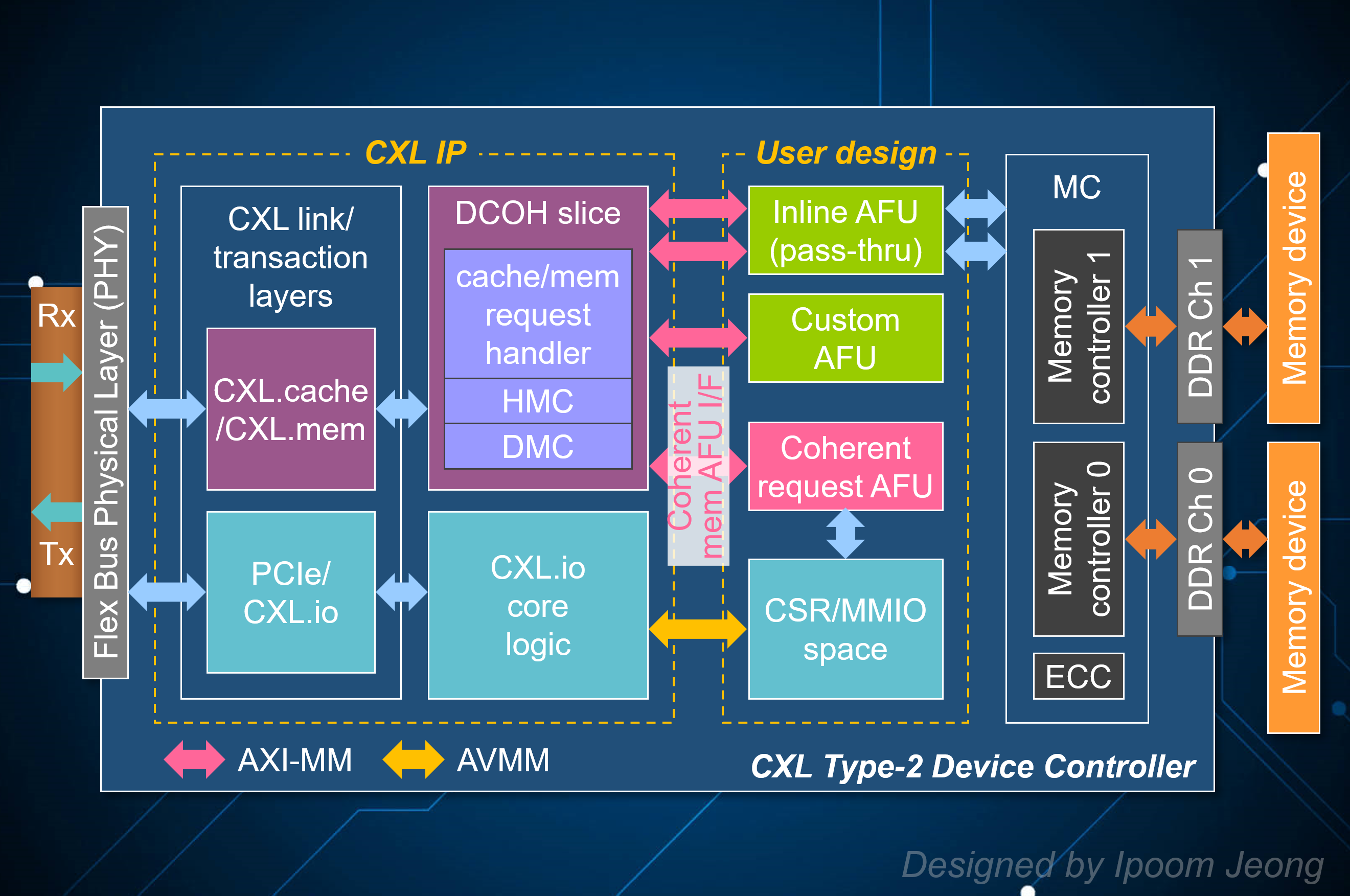
Compute Express Link (CXL) is an open standard for high-speed, efficient interconnects between CPUs and other devices such as memory, accelerators (e.g., GPUs, FPGAs), and SmartNICs (Network Interface Cards). It is designed to enhance performance and resource sharing in data centers, particularly in large-scale computing. We are exploring various use cases for CXL technology, including its potential to enable more flexible memory expansion, improve accelerator integration, and optimize data flow between heterogeneous computing components in next-generation data center architectures.
Representative Publications

System Architectures and Resource Orchestration
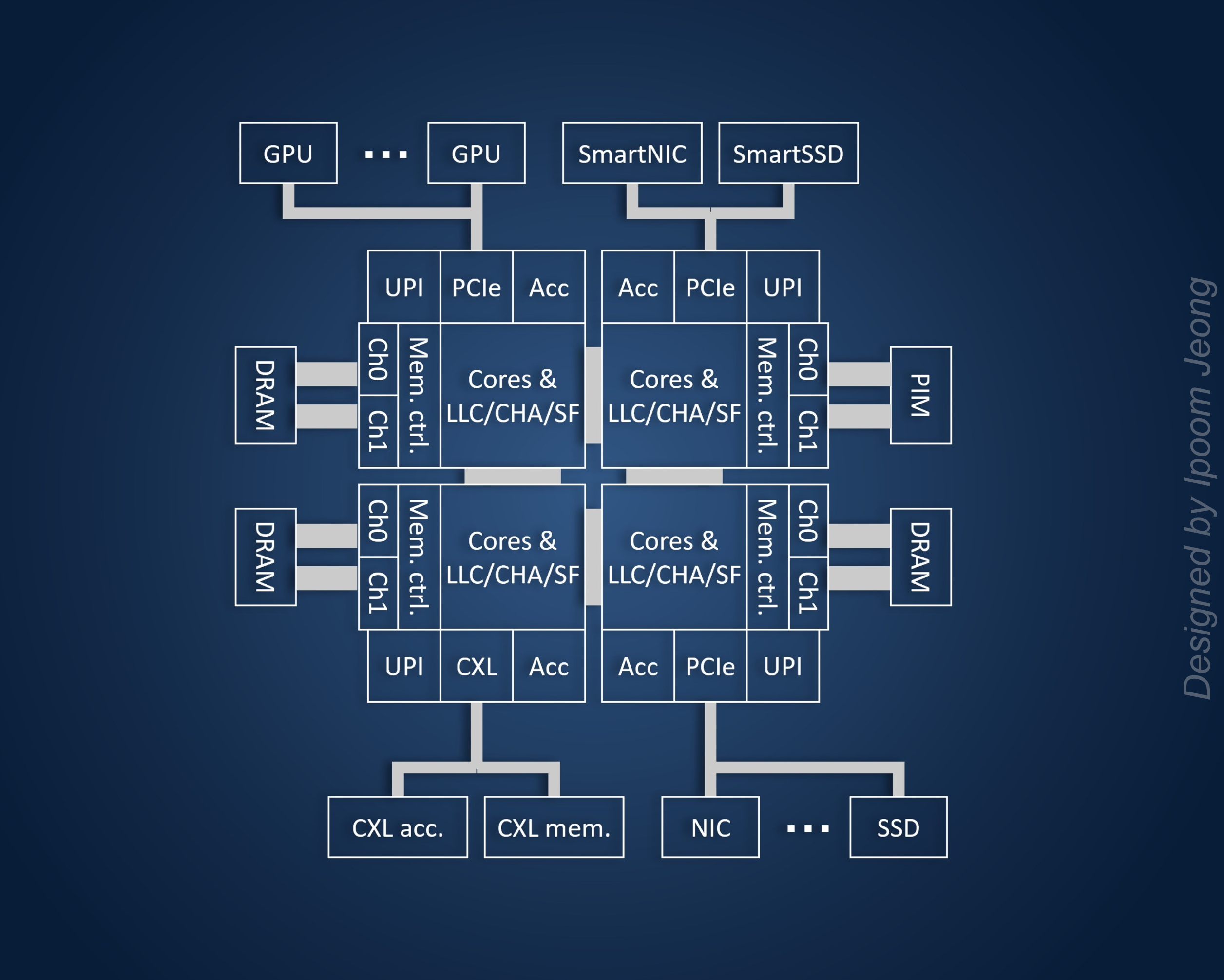
Modern computer systems have become larger and more complex, underscoring the need for designing highly efficient system architectures and effectively orchestrating shared resources, such as memory and Last-Level Cache (LLC). We are investigating cutting-edge systems and exploring diverse solutions to improve system-wide processing efficiency.
Representative Publications

Near-Data Processing
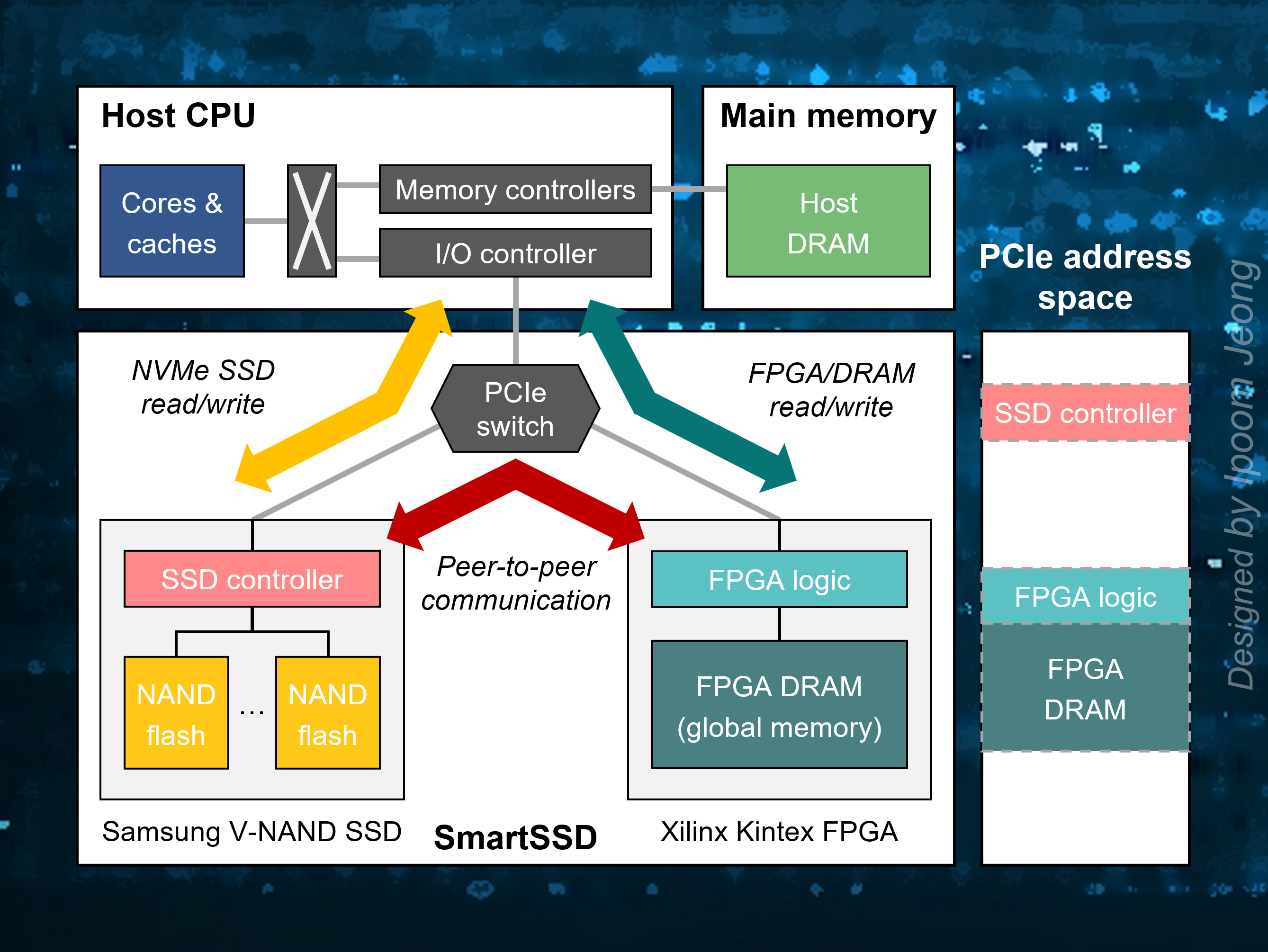
Data-centric applications encounter significant bottlenecks in transferring large volumes of data between processors and memory, storage, or networks. To address these challenges, we are investigating efficient near-data processing techniques at various system layers. This includes Processing-In-Memory (PIM), integrating processing capabilities directly into memory; In-Storage Processing (ISP), enabling data processing within storage devices; and In-Network Computing (INC), performing computations within the network infrastructure.
Representative Publications

Collaboration

University of Illinois Urbana-Champaign (UIUC), IL, United States

Yonsei University, Seoul, Republic of Korea